
Welkom bij weer een nieuwe blog over Coqfoss, ons interne project waarin we nieuwe dingen te leren door samen te werken. In deze reeks blogs nemen we je mee in de technieken die we gebruiken en delen de ervaringen die we opdoen. We zijn toe aan een wat permanentere oplossing voor data opslag. In deze blog gaan we bekijken hoe we met de principes van Clean Architecture onze modules opzetten .
Binnen het coqfoss project houden we ons niet alleen bezig met nieuwe technieken en gave libraries. We blijven ook zoet met het nadenken over de architectuur. Zo zijn we groot fan van de architectuurstijl die met een aantal namen door het leven gaat. Alistair Cockburn noemt het Hexagonal Architecture, maar wij noemen het vaak zoals Uncle Bob het noemt; Clean Architecture. Het grote voordeel van deze architectuur is dat het ons in staat stelt technische details van de core logica te scheiden. Als we dat goed doen, hebben we de mogelijkheid om eenvoudig hele modules te wisselen zonder dat we de kern van onze applicatie raken.
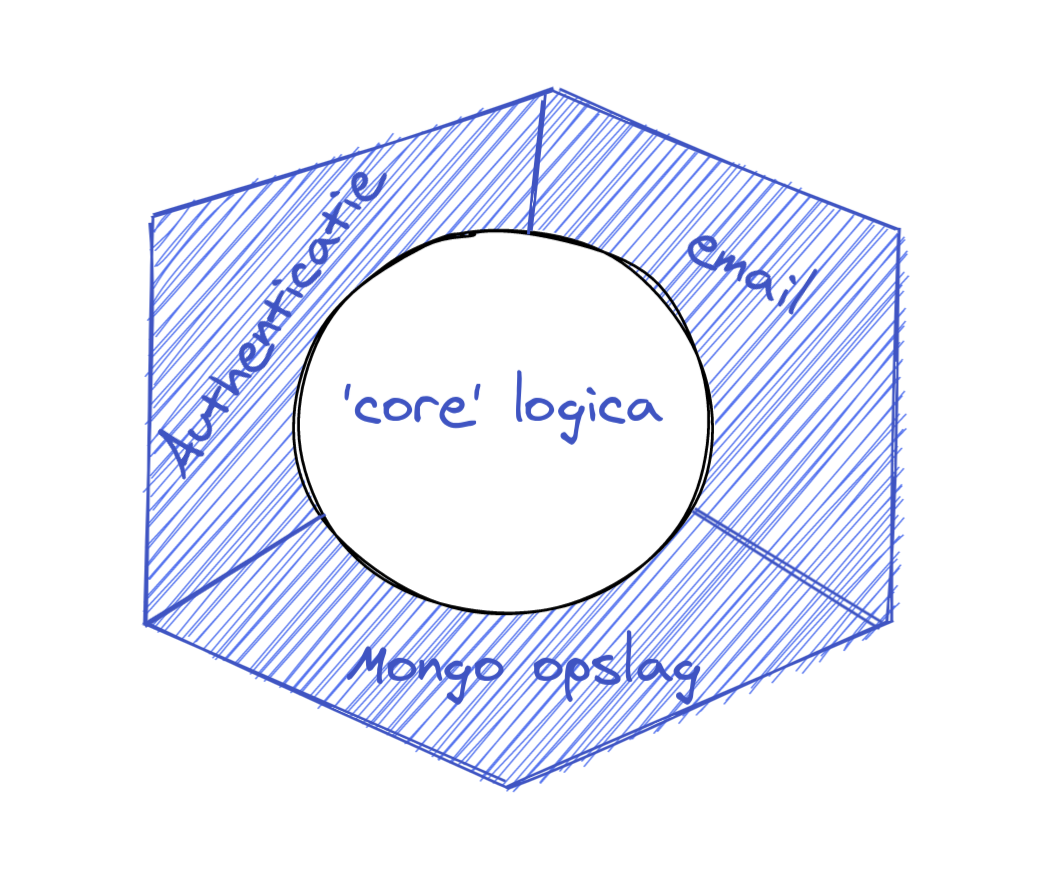
Een voorbeeld van een applicatie met een aantal modules
Een voorbeeld van zo’n technisch detail is de keuze voor MongoDB die we net hebben gemaakt. We zouden het graag zo hebben dat als we in de toekomst toch besluiten naar een Graph, SQL of andersoortige database over te stappen, dat we dan alleen de module voor opslag hoeven te vervangen.

Met een Clean Architecture is het mogelijk modules eenvoudig te wisselen
De ‘D’ van SOLID
Het hoe is gelukkig relatief eenvoudig. We maken in onze usecase module (hierboven aangeduid met core logica) een interface die beschrijft wat we precies van onze storage verwachten. We geven dus aan wat we willen opslaan of ophalen, maar een concrete implementatie ontbreekt nog. Vervolgens maken we een module voor opslag waar we die interface in implementeren. Daar weten we dan welk type opslag we gekozen hebben. We zorgen er voor dat er alleen een dependency loopt van de opslag module af naar de usecase module. Op die manier dwingen we af dat alleen de opslag module iets af weet van de technische details die bij de opslag horen. Via Dependency Injection zorgen we er dan weer voor dat de implementatie van de interface gebruikt kan worden in de usecase module.
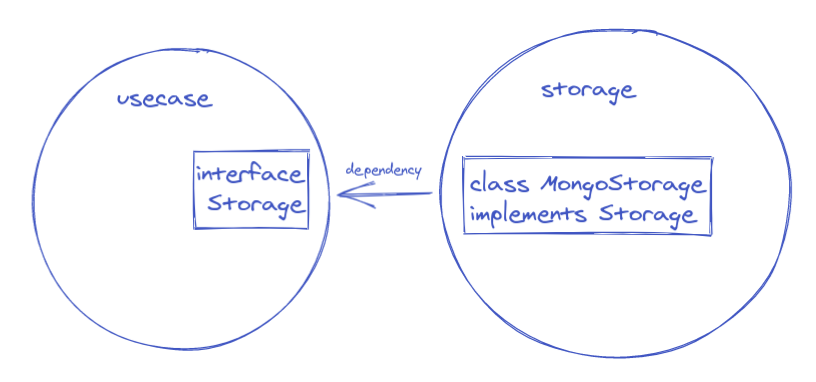
De interface en zijn implementatie
Als we een ander type opslag willen gaan gebruiken, doen we hetzelfde trucje nog een keer. We implementeren dan de interface opnieuw in een andere module met een andere techniek. Vervolgens kunnen we de nieuwe implementatie dan weer injecteren.
Dit trucje staat ook wel bekend als het Dependency Inversion Principle.
Alles aan elkaar binden
Het laatste belangrijke detail van de Clean Architecture is dat er wel iets moet zijn die uiteindelijk weet van alle verschillende modules en implementaties zodat we kunnen kiezen. Die plek wordt ook wel de main module genoemd.
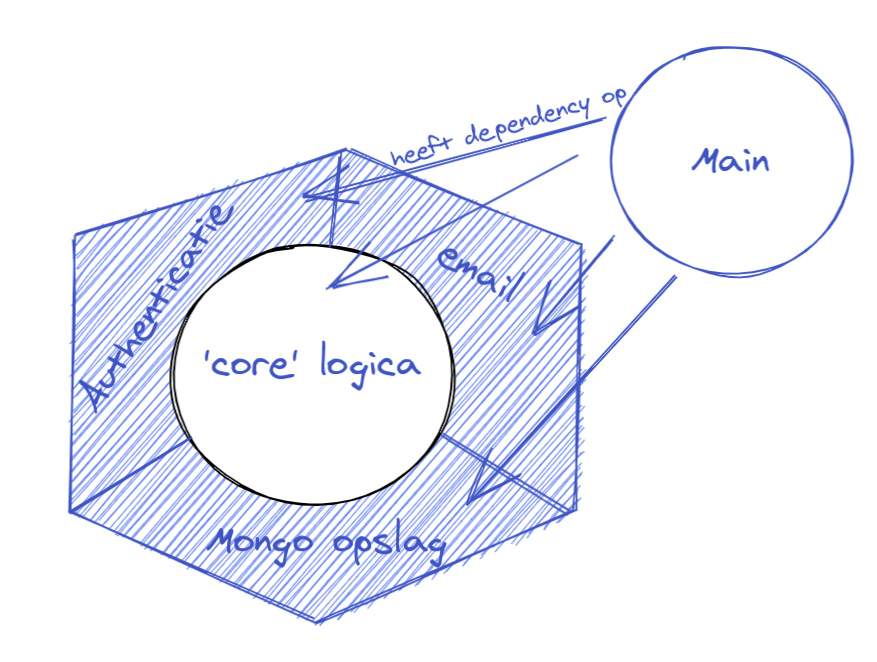
De applicatie met de main module
De main module is de ‘allervieste’ plek van onze applicatie. Hier komen alle technische details en dependencies samen om uiteindelijk de applicatie zelf tot een geheel te maken. Bij voorkeur is dit ook de plek waar je in een webcontext er voor zorgt dat je applicatie HTTP kan praten, en het liefst is dit ook de plek waar je aan de gang gaat met webframeworks.
Als we dat namelijk doen, kunnen we er voor zorgen dat onze usecase module (of core logica) alleen de standaard libraries nodig heeft. Daardoor zouden we als we moeten of willen zelfs relatief eenvoudig van webframework kunnen wisselen. We hoeven dan alleen de main module te vervangen!
Na deze uitstap in de abstractie gaan we de volgende blog terug naar Azure en bekijken we hoe we om kunnen gaan met secrets. Tot dan!